
Rechercher un élément d'un fichier CSV par la logique propositionnelle
- Fiche de cours
- Quiz et exercices
- Vidéos et podcasts
Rechercher des éléments d’un fichier CSV en utilisant la logique propositionnelle.
Pour rechercher un élément particulier dans un fichier CSV, il faudra utiliser des structures conditionnelles et parfois des opérateurs logiques.
- Connaitre les différents types de variables : int, float
- Transformer un fichier CSV en une liste utilisable par Python
- Utiliser les structures conditionnelles
- Utiliser les opérateurs logiques ET, OU, NON
Une fois le fichier CSV transformé en liste, on recherche des lignes de ce fichier dont les descripteurs répondent à différentes conditions.
On utilise pour cela :
- les structures conditionnelles : « if "condition1" else… » ou « if "condition1" elif&bsp;"condition2" else… » ;
- et les opérateurs logiques NON, ET, OU.
Lorsque le fichier CSV est transformé en liste, chaque élément est une chaine de caractères (l’élément est considéré comme du texte). On devra donc, en fonction du test, transformer l’élément en entier (commande int) ou en flottant (commande float).
Voici ci-dessous la traduction des tests en Python.
| En français | En Python |
| si A > B et C > D | if A>B and C>D: |
| si A > B ou C > D | if A>B or C>D: |
| si non A | if not A: |
Voici ci-dessous le fichier informaticien.csv et le programme Python.
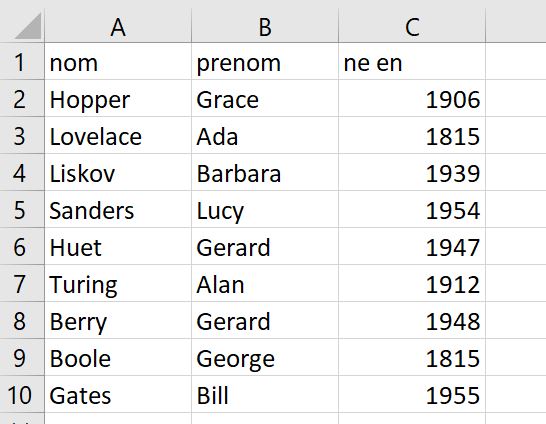
 Si on lance une
procédure de test directement sur la liste,
le descripteur va générer un message
d’erreur, on écrit donc les
lignes 6 et 7 qui vont permettre
d’afficher le descripteur utilisé.
Si on lance une
procédure de test directement sur la liste,
le descripteur va générer un message
d’erreur, on écrit donc les
lignes 6 et 7 qui vont permettre
d’afficher le descripteur utilisé.La ligne 8 indique que l’on comparera le 3e élément du descripteur (« 'ne en' ») de chaque ligne à 1850 et on testera si le prénom est Gérard.
On obtient l’affichage suivant.
['Huet', 'Gerard', '1947']
['Berry', 'Gerard', '1948']
La méthode .loc permet d’isoler des éléments du fichier.
Si on appelle data le fichier ouvert par Pandas, data['descripteur1'] permet d’afficher la colonne constituée de tous les descripteur1 de data.
Traduction des tests avec la bibliothèque Pandas :
| En français | Avec Pandas |
| A > B et C > D | (A>B) & (C>D) |
| A > B ou C > D | (A>B) | (C>D) |
Avec le même fichier informaticien.csv, le programme suivant permet de récupérer les lignes du fichier dont l’année de naissance est strictement supérieure à 1850 et dont le prénom est Gerard.
 On obtient l’affichage
suivant.
On obtient l’affichage
suivant.
| nom | prenom | ne en | |
| 4 | Huet | Gerard | 1947 |
| 6 | Berry | Gerard | 1948 |
Évalue ce cours !

Des quiz et exercices pour mieux assimiler sa leçon
La plateforme de soutien scolaire en ligne myMaxicours propose des quiz et exercices en accompagnement de chaque fiche de cours. Les exercices permettent de vérifier si la leçon est bien comprise ou s’il reste encore des notions à revoir.

Des exercices variés pour ne pas s’ennuyer
Les exercices se déclinent sous toutes leurs formes sur myMaxicours ! Selon la matière et la classe étudiées, retrouvez des dictées, des mots à relier ou encore des phrases à compléter, mais aussi des textes à trous et bien d’autres formats !
Dans les classes de primaire, l’accent est mis sur des exercices illustrés très ludiques pour motiver les plus jeunes.

Des quiz pour une évaluation en direct
Les quiz et exercices permettent d’avoir un retour immédiat sur la bonne compréhension du cours. Une fois toutes les réponses communiquées, le résultat s’affiche à l’écran et permet à l’élève de se situer immédiatement.
myMaxicours offre des solutions efficaces de révision grâce aux fiches de cours et aux exercices associés. L’élève se rassure pour le prochain examen en testant ses connaissances au préalable.

Des vidéos et des podcasts pour apprendre différemment
Certains élèves ont une mémoire visuelle quand d’autres ont plutôt une mémoire auditive. myMaxicours s’adapte à tous les enfants et adolescents pour leur proposer un apprentissage serein et efficace.
Découvrez de nombreuses vidéos et podcasts en complément des fiches de cours et des exercices pour une année scolaire au top !

Des podcasts pour les révisions
La plateforme de soutien scolaire en ligne myMaxicours propose des podcasts de révision pour toutes les classes à examen : troisième, première et terminale.
Les ados peuvent écouter les différents cours afin de mieux les mémoriser en préparation de leurs examens. Des fiches de cours de différentes matières sont disponibles en podcasts ainsi qu’une préparation au grand oral avec de nombreux conseils pratiques.
Des vidéos de cours pour comprendre en image
Des vidéos de cours illustrent les notions principales à retenir et complètent les fiches de cours. De quoi réviser sa prochaine évaluation ou son prochain examen en toute confiance !





Fiches de cours les plus recherchées


Envie de progresser et de réussir votre année scolaire ?
Testez gratuitement pendant 24h notre plateforme de soutien scolaire !

Un espace dédié aux parents pour suivre les progrès
Tout le programme scolaire du CP à la Terminale
Des profs expérimentés disponibles à la demande par tchat, audio ou vidéo