
Se déplacer dans un graphe
- Fiche de cours
- Quiz et exercices
- Vidéos et podcasts
- Parcourir un graphe en profondeur d’abord.
- Parcourir un graphe en largeur d’abord.
- Chercher des chemins dans un graphe entre deux sommets.
- Le parcours en profondeur d’abord d’un graphe détermine tous les nœuds accessibles à partir d’un sommet donné.
- Le parcours en largeur d’abord d’un graphe explore les nœuds du graphe en les classant du plus proche au plus éloigné.
- Comprendre la structure hiérarchique de graphe.
- Savoir implémenter un graphe.
- Comprendre la structure de données file.
Chaque parcours définit l’ordre de parcours des nœuds.
Le nom anglais est DFS pour depth-first search.
L’un des buts principaux du parcours en profondeur d’abord est de trouver tous les nœuds accessibles depuis un sommet du graphe.
parcours_profondeur_rec(graphe, sommet, visite).
Cette fonction prend en paramètres :
- graphe un graphe implémenté avec une liste d’adjacence ;
- sommet un sommet à partir duquel on réalise le parcours en profondeur ;
- visite un tableau des nœuds déjà visités.
Cette fonction renvoie la liste du parcours en profondeur d’abord du graphe à partir du sommet.
La liste d’adjacence a une structure de dictionnaire qui a pour clés les sommets et pour valeurs associées aux clés les listes des sommets adjacents.
Voici ci-dessous l’implémentation de cette fonction.
| Python | Explication |
| def parcours_profondeur_rec(graphe, sommet, visite = None): |
On définit la fonction. Le tableau visite est initialisé comme étant None. |
|
if visite is None: visite = [] |
Si visite vaut None, on affecte un tableau vide à visite. |
|
if sommet not in visite: visite.append(sommet) |
Si le sommet n’est pas visité, on l’ajoute au tableau visite. |
|
non_visite = [s for s in graphe[sommet] if s not in visite] |
On crée un tableau non_visite des nœuds adjacents au sommet qui n’ont pas encore été visités. |
|
for s in non_visite: parcours_profondeur_rec (graphe, s, visite) |
À partir de chaque nœud s non visité, on fait un parcours en profondeur |
| return visite | On retourne le tableau visite. |
On considère le graphe suivant.
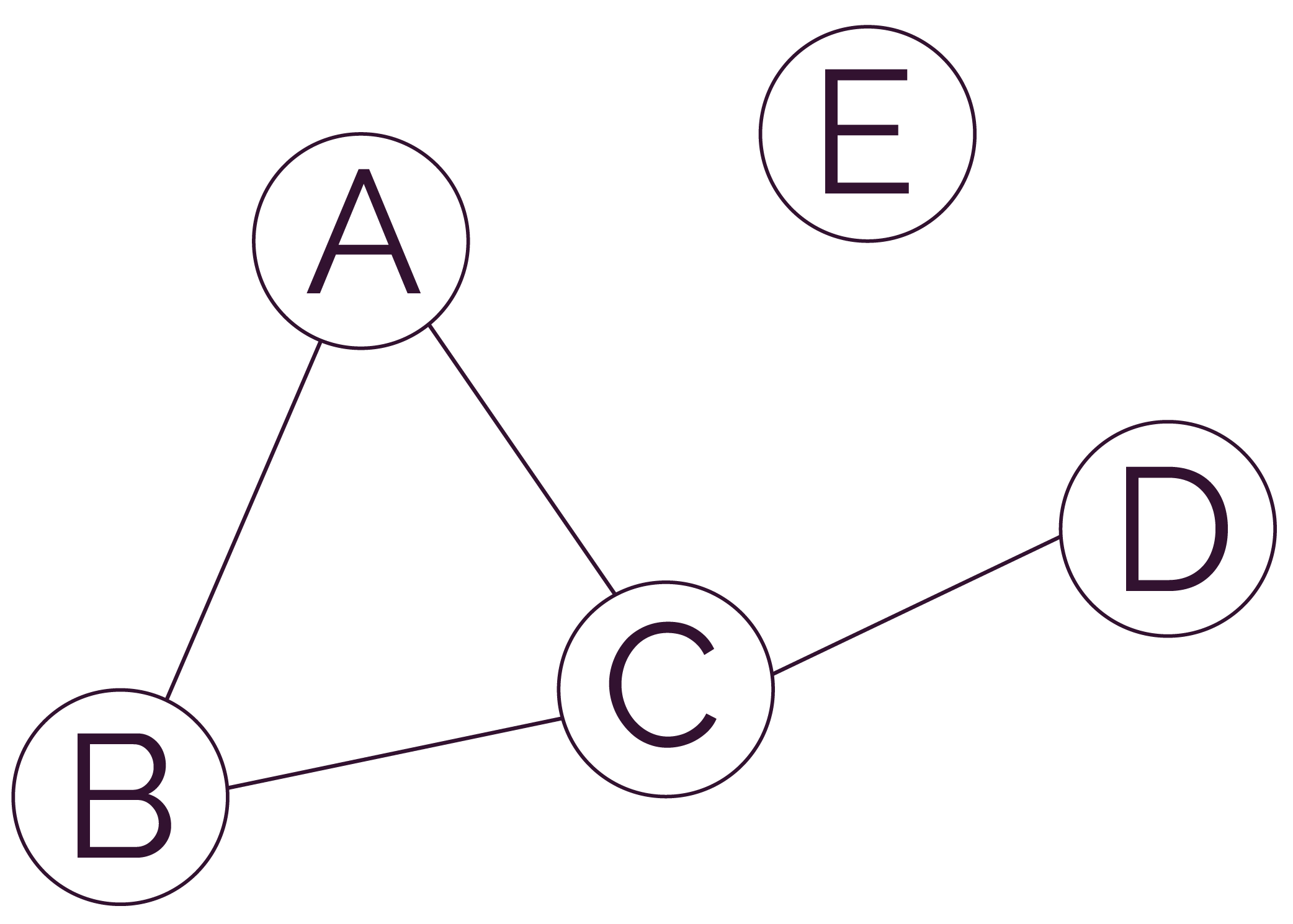
graphe = {'A' : ['B', 'C'], 'B' : ['A', 'C'], 'C' : ['A', 'B', 'D'], 'D' : ['C'], ‘E’ : []}
Voici l’exécution sur Python Tutor de la fonction parcours_profondeur_rec(graphe, ‘C’).
Le parcours en profondeur de ce graphe d’abord à partir du sommet ‘C’ est donc [‘C’, ‘A’, ‘B’, ‘D’].
Le nom anglais est BFS pour breadth-first search.
L’un des buts principaux du parcours en largeur d’abord est de trouver tous les nœuds accessibles depuis un sommet en les ordonnant, du plus proche au plus éloigné.
On considère le graphe suivant.
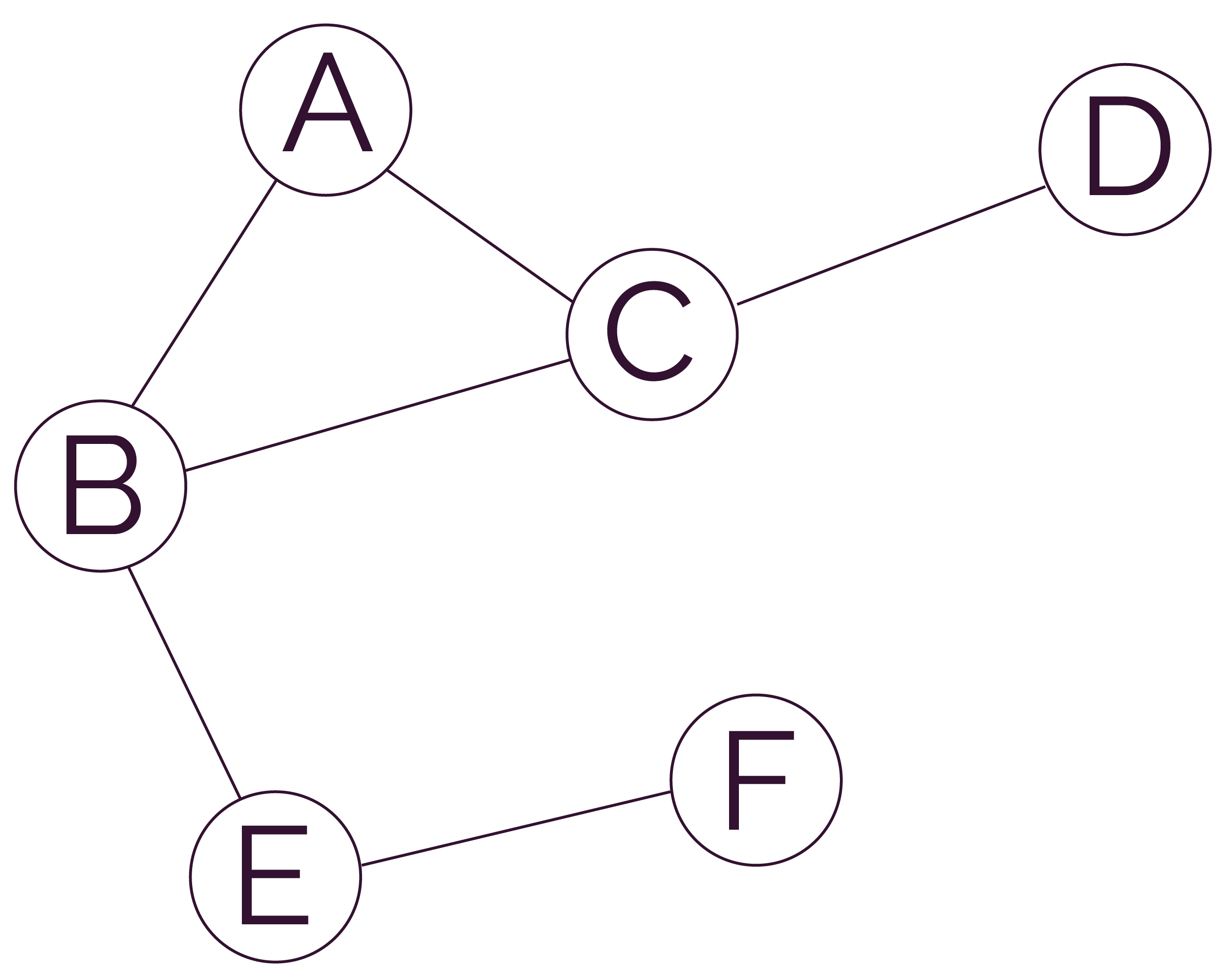
- Distance 0 : ‘D’ ;
- Distance 1 : ‘C’ est le seul
nœud
à une distance de 1 arête de ‘D’ ; - Distance 2 : ‘A’ et
‘B’
sont les nœuds
à une distance de 2 arêtes de ‘D’ ; - Distance 3 : ‘E’ est le seul
nœud
à une distance de 3 arêtes de ‘D’ ; - Distance 4 : ‘F’ est le seul
nœud
à une distance de 4 arêtes de ‘D’.
En effet, les nœuds à la distance 2 ne sont pas ordonnés. Leur ordre d’apparition dans le parcours en largeur d’abord dépend de la manière dont la liste d’adjacence du graphe est construite.
Dans une file, on enfile et défile des données : les premiers éléments ajoutés à une file seront les premiers à être récupérés.
Pour implémenter la file en Python, on utilise un objet de type list avec la méthode append pour enfiler (ajouter un élément à la file) et l’instruction file.pop(0) pour défiler (retirer le premier élément de la file).
Cette fonction prend en paramètres :
- graphe un graphe implémenté avec une liste d’adjacence ;
- sommet un sommet à partir duquel on réalise le parcours en profondeur.
Cette fonction renvoie la liste du parcours en largeur d’abord du graphe à partir du sommet.
Voici ci-dessous l’implémentation de cette fonction.
| Python | Explication |
| def parcours_largeur(graphe, sommet): | On définit la fonction. |
|
visite = [] file = [] file.append(sommet) |
On initialise la liste des nœuds visités visite à []. On initialise la file utilisée file à [sommet]. |
|
while file: s = file.pop(0) |
Tant que file n’est pas vide, on défile file. Le nœud récupéré est s. |
|
if s not in visite: visite.append(s) |
Si s n’a pas été visité, alors on l’ajoute au tableau visite. |
|
non_visite = [n for n in graphe[s] if n not in visite] |
On crée un tableau non_visite des nœuds adjacents au nœud s qui n’ont pas encore été visités. |
| file.extend(non_visite) | On enfile dans file tous les éléments du tableau non_visite. |
| return visite | On retourne le tableau visite. |
Dans cette fonction, la file est successivement défilée (retrait d’un élément), remplie, défilée, remplie, etc. On sort de la boucle while lorsque la file est vide.
On considère le graphe suivant.
On implémente ce graphe avec une liste d’adjacence :
graphe = {'A' : ['B', 'C'], 'B' : ['A', 'C', 'E'], 'C' : ['A', 'B', 'D'], 'D' : ['C'], 'E' : ['B', 'F'], 'F' : ['E']}Voici l’exécution sur Python Tutor de la fonction parcours_profondeur_rec(graphe, ‘D’).
Le parcours en largeur de ce graphe à partir du sommet ‘D’ est donc [‘D’, ‘C’, ‘A’, ‘B’, ‘E’, ‘F’].
On peut adapter le code de la fonction précédente pour que la file stocke au fur et à mesure le tuple (nœud, chemin). Ainsi, en précisant le nœud de départ et le nœud d’arrivée, on peut récupérer tous les chemins qui relient ces deux nœuds.
On considère le graphe orienté suivant (attention : les arcs sont orientés).
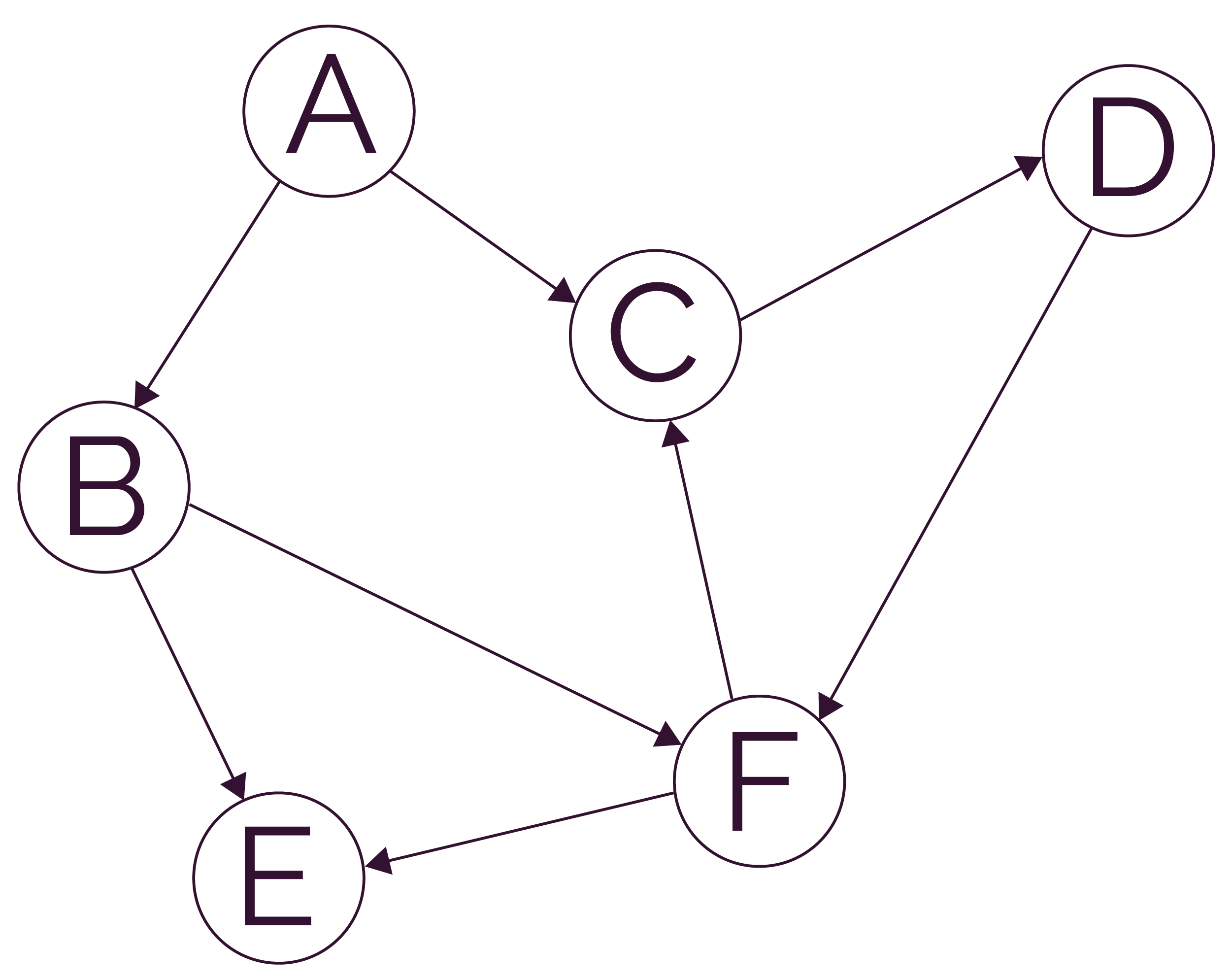
- ‘A’ — ‘B’ — ‘F’
- ‘A’ — ‘C’ — ‘D’ — ‘F’
Cette fonction prend en paramètres :
- graphe un graphe implémenté avec une liste d’adjacence ;
- nœud_init et nœud_fin deux sommets.
Cette fonction renvoie la liste des chemins du graphe de nœud_init à nœud_fin.
Voici ci-dessous l’implémentation de cette fonction.
| Python | Explication |
| def recherche_chemin(graphe, nœud_init, nœud_fin): | On définit la fonction. |
|
file = [] file.append((nœud_init, [nœud_init])) chemins = [] |
On initialise la file utilisée file à [(nœud_init, [nœud_init])]. On initialise la liste des chemins à []. |
|
while file: sommet, chemin = file.pop(0) |
Tant que file n’est pas vide, on défile file. On récupère sommet un nœud et un tableau chemin. (Chemin est le chemin en cours de traitement.) |
|
for s in graphe[sommet]: if s not in chemin: |
Pour chaque voisin s de sommet qui n’est pas dans chemin, |
|
if s == nœud_fin: chemins.append(chemin + [s]) |
si s est le nœud final nœud_fin, alors on a ajoute le chemin chemin+[s] au tableau chemins. (Chemins est la liste de tous les chemins possibles que l'on rajoute au fur et à mesure.) |
|
else: file.append((s, chemin + [s])) |
sinon, on ajoute à file le tuple (s,chemin+[s]). |
| return chemins | On retourne le tableau chemins. |
On considère le graphe suivant.
On implémente ce graphe avec une liste
d’adjacence :
graphe = {'A' : ['B', 'C'], 'B' : ['E', 'F'], 'C': ['D'], 'D' : ['F'], 'E' : [], 'F' : ['C', 'E']}
Voici l’exécution sur Python Tutor de la fonction recherche_chemin(graphe, 'A', 'F').
Les chemins du graphe entre le sommet ‘A’ et le sommet ‘F’ sont donc ['A', 'B', 'F'] et ['A', 'C', 'D', 'F'].
Évalue ce cours !

Des quiz et exercices pour mieux assimiler sa leçon
La plateforme de soutien scolaire en ligne myMaxicours propose des quiz et exercices en accompagnement de chaque fiche de cours. Les exercices permettent de vérifier si la leçon est bien comprise ou s’il reste encore des notions à revoir.

Des exercices variés pour ne pas s’ennuyer
Les exercices se déclinent sous toutes leurs formes sur myMaxicours ! Selon la matière et la classe étudiées, retrouvez des dictées, des mots à relier ou encore des phrases à compléter, mais aussi des textes à trous et bien d’autres formats !
Dans les classes de primaire, l’accent est mis sur des exercices illustrés très ludiques pour motiver les plus jeunes.

Des quiz pour une évaluation en direct
Les quiz et exercices permettent d’avoir un retour immédiat sur la bonne compréhension du cours. Une fois toutes les réponses communiquées, le résultat s’affiche à l’écran et permet à l’élève de se situer immédiatement.
myMaxicours offre des solutions efficaces de révision grâce aux fiches de cours et aux exercices associés. L’élève se rassure pour le prochain examen en testant ses connaissances au préalable.

Des vidéos et des podcasts pour apprendre différemment
Certains élèves ont une mémoire visuelle quand d’autres ont plutôt une mémoire auditive. myMaxicours s’adapte à tous les enfants et adolescents pour leur proposer un apprentissage serein et efficace.
Découvrez de nombreuses vidéos et podcasts en complément des fiches de cours et des exercices pour une année scolaire au top !

Des podcasts pour les révisions
La plateforme de soutien scolaire en ligne myMaxicours propose des podcasts de révision pour toutes les classes à examen : troisième, première et terminale.
Les ados peuvent écouter les différents cours afin de mieux les mémoriser en préparation de leurs examens. Des fiches de cours de différentes matières sont disponibles en podcasts ainsi qu’une préparation au grand oral avec de nombreux conseils pratiques.
Des vidéos de cours pour comprendre en image
Des vidéos de cours illustrent les notions principales à retenir et complètent les fiches de cours. De quoi réviser sa prochaine évaluation ou son prochain examen en toute confiance !





Fiches de cours les plus recherchées


Envie de progresser et de réussir votre année scolaire ?
Testez gratuitement pendant 24h notre plateforme de soutien scolaire !

Un espace dédié aux parents pour suivre les progrès
Tout le programme scolaire du CP à la Terminale
Des profs expérimentés disponibles à la demande par tchat, audio ou vidéo