
Représenter un texte en utilisant différents encodages
- Fiche de cours
- Quiz et exercices
- Vidéos et podcasts
Comprendre la représentation d’un texte en machine.
Pour représenter un texte, on utilise différents encodages : l’ASCII qui est plus ancien et limité, et l’Unicode qui permet d’encoder pratiquement tous les glyphes.
- Codage sur 8 bits ou plus
- Conversion binaire/décimal
Les caractères sont des symboles alphanumériques : majuscules, minuscules, chiffres, ponctuation, caractères spéciaux, etc. À chaque caractère correspond un nombre en binaire.
En 1960, on normalise l’écriture avec l’ASCII de base (American Standard Code for Information Interchange), prononcé « aski ». À chaque caractère est associé un binaire sur 7 bits. Il y a donc 27 = 128 caractères numérotés de 010 à 12710 et codés en binaire de 00000002 à 11111112.
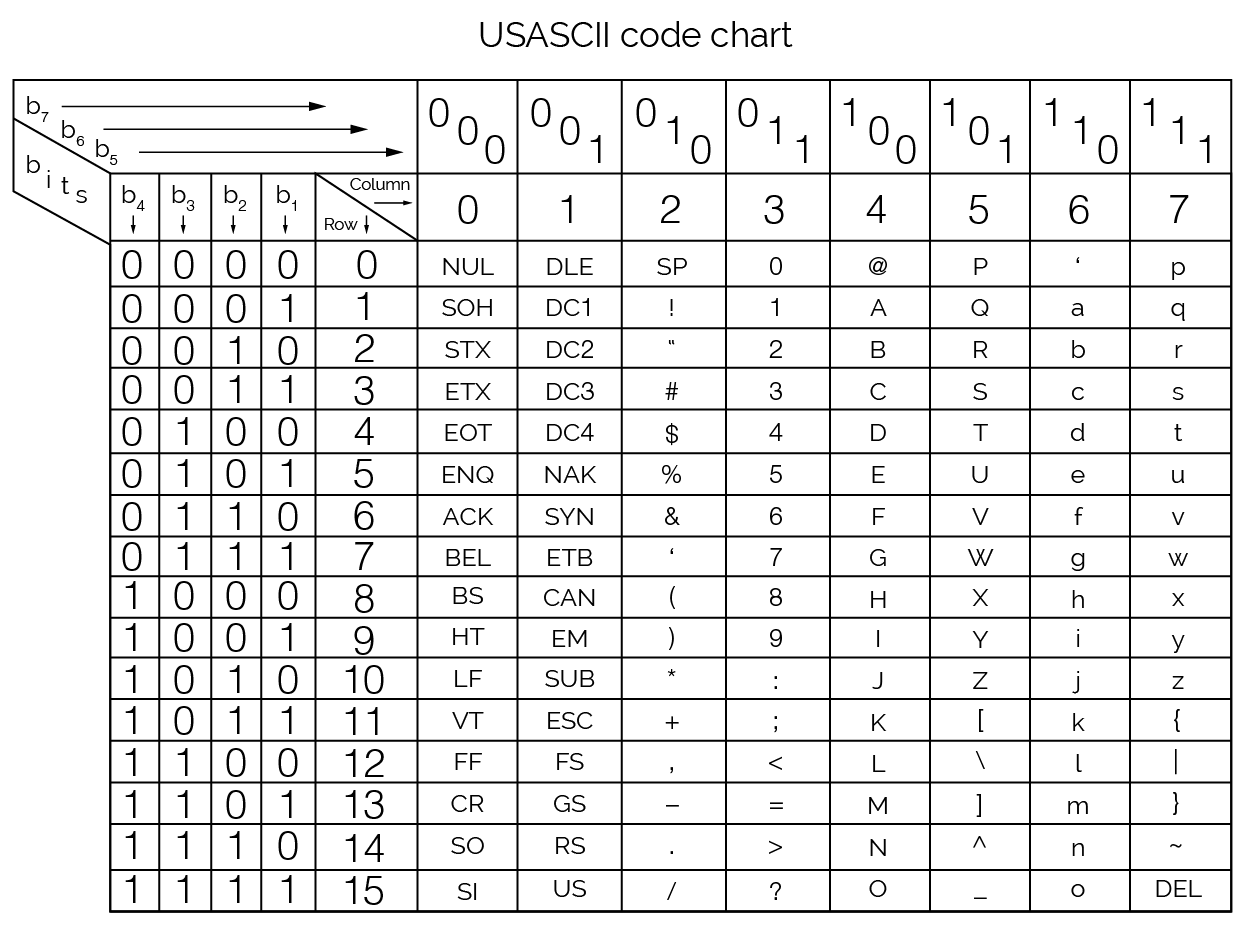
Table ASCII
P en ASCII : 10100002. En effet, les 3 premiers bits sont donnés par le numéro de colonne associé à P, c’est-à-dire 101, puis les quatre autres bits sont donnés par le numéro de la ligne, ici 0000.
Le code ASCII de P en décimal vaut 8010.

Le code ASCII utilisant 7 bits, il faudra souvent rajouter à gauche un huitième bit égal à 0 pour pouvoir écrire le caractère sur 1 octet (8 bits). Pour ajouter les accents, on utilise le 8e bit dans l’ASCII étendu.
Beaucoup de langues n’utilisent pas l’alphabet latin, ce qui cause beaucoup de problèmes (par exemple les glyphes des alphabets russes ou arabes). Une nouvelle norme a donc été créée en 1991 : l’Unicode.
Le but est de rassembler tous les caractères existants, la table Unicode contient donc près de 150 000 caractères. Le codage de cette table est multiple.
Le codage le plus utilisé est l’UTF-8 qui fonctionne sur le principe suivant.
Principe du codage UTF-8
- Les caractères « classiques » sont codés sur 1 octet.
- Les caractères moins classiques, plus rares, sont codés sur un nombre variable d’octets (2, 3 ou 4).
Les 128 premiers caractères de la table UTF-8 sont compatibles avec le codage ASCII. Les caractères simples Unicode codés avec UTF-8 ont exactement le même code que les mêmes caractères en ASCII.
Il est important, quand on veut décoder un texte, de savoir quel est le codage utilisé, sinon le message risque d’être incompréhensible.
Évalue ce cours !

Des quiz et exercices pour mieux assimiler sa leçon
La plateforme de soutien scolaire en ligne myMaxicours propose des quiz et exercices en accompagnement de chaque fiche de cours. Les exercices permettent de vérifier si la leçon est bien comprise ou s’il reste encore des notions à revoir.

Des exercices variés pour ne pas s’ennuyer
Les exercices se déclinent sous toutes leurs formes sur myMaxicours ! Selon la matière et la classe étudiées, retrouvez des dictées, des mots à relier ou encore des phrases à compléter, mais aussi des textes à trous et bien d’autres formats !
Dans les classes de primaire, l’accent est mis sur des exercices illustrés très ludiques pour motiver les plus jeunes.

Des quiz pour une évaluation en direct
Les quiz et exercices permettent d’avoir un retour immédiat sur la bonne compréhension du cours. Une fois toutes les réponses communiquées, le résultat s’affiche à l’écran et permet à l’élève de se situer immédiatement.
myMaxicours offre des solutions efficaces de révision grâce aux fiches de cours et aux exercices associés. L’élève se rassure pour le prochain examen en testant ses connaissances au préalable.

Des vidéos et des podcasts pour apprendre différemment
Certains élèves ont une mémoire visuelle quand d’autres ont plutôt une mémoire auditive. myMaxicours s’adapte à tous les enfants et adolescents pour leur proposer un apprentissage serein et efficace.
Découvrez de nombreuses vidéos et podcasts en complément des fiches de cours et des exercices pour une année scolaire au top !

Des podcasts pour les révisions
La plateforme de soutien scolaire en ligne myMaxicours propose des podcasts de révision pour toutes les classes à examen : troisième, première et terminale.
Les ados peuvent écouter les différents cours afin de mieux les mémoriser en préparation de leurs examens. Des fiches de cours de différentes matières sont disponibles en podcasts ainsi qu’une préparation au grand oral avec de nombreux conseils pratiques.
Des vidéos de cours pour comprendre en image
Des vidéos de cours illustrent les notions principales à retenir et complètent les fiches de cours. De quoi réviser sa prochaine évaluation ou son prochain examen en toute confiance !





Fiches de cours les plus recherchées


Envie de progresser et de réussir votre année scolaire ?
Testez gratuitement pendant 24h notre plateforme de soutien scolaire !

Un espace dédié aux parents pour suivre les progrès
Tout le programme scolaire du CP à la Terminale
Des profs expérimentés disponibles à la demande par tchat, audio ou vidéo